在全局的角度对TCP/IP编程的解读,我大概翻阅了其中的TCP部分,暂且跳过UDP部分。
Item 1 基于连接与无连接的区别
所谓无连接的协议,是说每个数据包(ip层之上)都是彼此独立处理的,每个数据报(datagram)独立编址并发送,所以说网络层尽力去传输每个数据包,但难以保证不丢失。
- 面向连接是说连续的数据传送中维护了状态信息,以实现tcp stack的特性,可靠传输。
- IP层是整个TCP Protocol的基础,它提供了很好的高效、不可靠、无连接的服务,将上层给的数据封装到IP数据包内,路由其到硬件正确的接口上,然后,他就不管了,有意思的是,IP层这种方式没有对下层物理介质做任何假设于是可以运行在传输数据包的网络上,于是TCP也可以,好醒目。
- TCP为了提供可靠性,添加了验校位,添加了序列号,还有确认和重传的机制
Item 2 子网和CIDR
- ignored
Item 3 私有地址和NAT
- NAT设备:路由器,防火墙等内部存储了内部ip:port的状态表,对外转换成公网IP
Item 4 Using Framework
- ignored
Item 5 使用socket而不是xxxx
- ignored
Item 6 TCP是一个流协议
- stream protocol,意味着数据是以字节流递交给接收者,也就是说,调用读取之前,并不知道会返回多少字节。
- a example:发送方发送:M1、M2,但接收者可能会得到多种组合的数据流:
1.M1,M21,M22
2.M11,M12,M22
3.M1,M2
4.M11,M12,M21,M22 - 如上所示,对于TCP Application来说,没有数据包的说法
- 解决办法?见网络库设计的惯用法吧~~
Item 7 别低估TCP的性能
- 晚点来读
Item 8 别彻底改造TCP
- 什么鬼,why would people do that?
- 哦,有人需要TCP级别的事务扩展,OTZ,请看MVCC啦
- RTO计时器的超时重传时间不该写死,应该考虑RTT,网络情况变化时,
合理地校正计时器
Item 9 TCP是可靠但并非不会出错
- 所谓TCP的可靠性,描述了啥
- 问题1:谁对谁保证了可靠性?其实发送方对接收方收到的TCP段不做保证,但接收方会对发送方做保证:他收到的任何数据以及之前到达的都是在TCP层上正确收到了,然后发送方就可以淡定地丢弃发送过的数据(当然不是说application正确收到了,万一他在此之前挂了呢)。
- OH,其实也不一定100%收到的数据就是准确的,因为TCP中使用的是字节对的16bit偶校验和,能检测<=15bit的突发错,误判率不高于1/(2^16-1).
- 总结起来,失败模式包括:经过TCP确认的数据可能不能到底application层
- 只要保持连接,TCP就能报障按顺序递交数据,并且数据不会被破坏,但是,1.网络紊乱,由于以太网接口松了,路由器失败等导致,此时TCP stack不能立刻意识到问题,直到发送方放弃(大概9分钟),写操作返回一个SIGPIPE信号
2.对端崩溃,
以上说的不一定对啊,陈硕先生在博文中提到
- “IP header里边有check sum,TCP header也有check sum,链路层以太网还有CRC32校验,那么为什么还需要在应用层做校验?什么情况下TCP传送的数据会出错?IP header和TCP header的check sum是一种非常弱的16-bit check sum算法,把数据当成反码表示的16-bit integers,再加到一起。这种checksum算法能检出一些简单的错误,而对某些错误无能为力,由于是简单的加法,遇到“和”不变的情况就无法检查出错误(比如交换两个16-bit整数,加法满足交换律,结果不变)。以太网的CRC32只能保证同一个网段上的通信不会出错(两台机器的网线插到同一个交换机上,这时候以太网的CRC是有用的)。但是,如果两台机器之间经过了多级路由器呢?
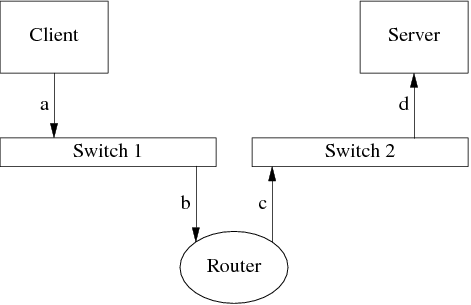
上图中Client向Server发了一个TCP segment,这个segment先被封装成一个IP packet,再被封装成ethernet frame,发送到路由器(图中消息a)。Router收到ethernet frame (b),转发到另一个网段(c),最后Server收到d,通知应用程序。Ethernet CRC能保证a和b相同,c和d相同;TCP header check sum的强度不足以保证收发payload的内容一样。另外,如果把Router换成NAT,那么NAT自己会构造c(替换掉源地址),这时候a和d的payload不能用tcp header checksum校验。
路由器可能出现硬件故障,比方说它的内存故障(或偶然错误)导致收发IP报文出现多bit的反转或双字节交换,这个反转如果发生在payload区,那么无法用链路层、网络层、传输层的check sum查出来,只能通过应用层的check sum来检测。这个现象在开发的时候不会遇到,因为开发用的几台机器很可能都连到同一个交换机,ethernet CRC能防止错误。开发和测试的时候数据量不大,错误很难发生。之后大规模部署到生产环境,网络环境复杂,这时候出个错就让人措手不及。
这个情况真的会发生吗?会的,Amazon S3 在2008年7月就遇到过,单bit反转导致了一次严重线上事故,所以他们吸取教训加了 check sum。见http://status.aws.amazon.com/s3-20080720.html
另外一个例证:下载大文件的时候一般都会附上MD5,这除了有安全方面的考虑(防止篡改),也说明应用层应该自己设法校验数据的正确性。这是end-to-end principle的一个例证。
Item 10 TCP不是轮询(地检测链接是否unavailable)
- 上节说道的对端崩溃,本机TCP Stack不能立即感知,原因是,这是国防部当年的主要设计目标:对抗自然灾害等引起的网络暂时不可用,tcpstack 已经处理好这种异常(而不是application层去做)
- Keep-Alive 检测死链接,并移除他们(这可能并不是application想要的),而且他的间隔时间太长了,bsd的实现是2个小时11分
- application层的heartbeats是必要的,
Item 11 为来自对等方的不合理请求行为做准备
- setsocketopt试试keepalive,todo
Item 12 LAN策略与WAN策略
- ignored
Item 13 多学习协议是如何工作的
- 大多数问题是你对下层网络协议不理解造成的,比如只有Nagle算法扮演的角色才能知道什么时候可以禁用它。(TODO)
Item 14 Ignore OSI
- ignored
Item 15 理解TCP的写操作
- 除非TCP发送缓冲区已经满,否则写操作是不会阻塞,立即返回的。
- TCP发送机制的基本目标是尽可能地高效使用带宽,为了达到这个目的,TCP使用MMS大小发送数据块。
- TCP先一开始发一个段,然后增加网络中没有确认的段的数量,直到达到了稳定状态。
- 预防拥塞?使用额外的拥塞窗口来控制拥塞,TCP发送的是min{发送窗口,拥塞窗口},前者是由对等方使用,以免超过对方的缓冲区,拥塞窗口是本方使用,以预防application发送网络所能承受的能力。
- Nagle算法的目的是避免TCP发送一系列的小段数据给网络造成数据泛滥,TCP在接收前一小段的ACK前,一直保持数量很小的数据。
- Nagle example:一空闲链接,发送拥塞窗口都很大,application执行俩个写操作, 因为窗口很大,Nagle算法也因未有未确认的数据而反对发送数据,于是第一个写操作立即发送出去了,然而因为仍有未确认的数据,第二次写操作会不会立即发送。
Item 16 理解TCP顺序释放操作
- shutdown(fd,how) API提供的初衷是因为不能粗暴地关闭socket,因为可能对端仍有数据在发送,有额外的参数指示要关闭哪一方的连接
- how=0,关闭接收方,此时不能再接收任何数据了,unix会丢弃application没有读取的任何数据,如果有新数据到达,TCP确认了他们后悄悄丢弃了,而winsocket则如果队列中有数据或者新数据到达,就重置连接(被认为是不安全的)
- how=1,关闭发送方,不能发送任何数据了,否则返回错误,buffer中的数据发送完毕后,TCP给对端发送一个FIN,告诉对端我没有任何数据要发送了,这叫半关闭,这是shutdown最常用的场景。
- how=2,关闭双方连接
- close与shutdown有显著不同,后者并未关闭socket,任何socket与他的资源都未被释放,而close时,该socket的其他拥有者仍可以使发送数据(todo,纳尼??)也就是说,调用close后也不能保证一定会发FIN给对端,直到该socket的reference count为0。
- 实验与代码(todo)
- Item 17 考虑inetd来启动程序
- ignored
Item 18 tcpmux来指定端口
- ignored
Item 19 考虑两个TCP连接
- wired,ignored
Item 20 考虑使用事件驱动
- will talk later in other blog,ignored
Item 21 TIME-WAIT Assassination不能帮忙关闭连接
- time-wait其实被TCP状态机隐藏了,很少人知道他的用途和重要性。
- A发送一个FIN给B,B确认这个FIN消息,回复一个ACK,接着,B也关闭他那端的连接,接着发一个FIN给A,A返回一个ACK。
- 从这以后,B关闭连接,释放资源,因为他认为,这个连接已经不存在了
- A则进入TIME-WAIT状态,设置为2倍的最大生存时间,之后,他关闭并释放资源
从上述例子中可以看出TIME-WAIT的特点 - 通常情况下,仅有一方(主动关闭操作的一方)进入TIME-WAIT状态
- TIME-WAIT状态时,有数据到达,则重新启动2MSL计时器
为何需要TIME-WAIT?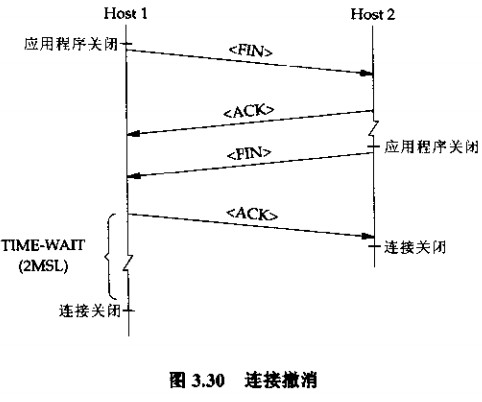
如上图,TIME-WAIT发生的典型场景,主动关闭的一方才会进入TIME-WAIT(如果同时关闭,那么他们会同时进入TIME-WAIT状态),BSD派生的系统时常大概为30s~2分钟。
- 上图中HOST 1发送的ACK如果丢失,HOST 2将会重新发送FIN,TIME-WAIT状态就是在维护这种连接状态。如果没有TIME-WAIT,HOST 2重新发送的FIN HOST 1无法认识,于是他回复一个RST(重新启动),这样HOST 2就进入错误的状态(而不是有序终止的状态)
- TCP通过窗口处理重传数据,如果延迟的数据在当前接收窗口之外,丢弃之,如上所说,如果重传或延迟的段在连接关闭后达到,将丢弃并返回RST消息,问题是当对端收到该RST时,一条基于相同主机相同端口的新连接如果存在,而恰好该数据的seq序列号在新连接的接收窗口中,数据就会被接收,新连接就被破坏了。
- TCP通过 TIME-WAIT确保旧socket对(两个相同IP,相同端口)的迷失的数据报在网络上消失之前,不会被重用。
TIME-WAIT Assassination
RFC说确实存在上面讨论的过早关闭TIME-WAIT状态的可能性,被称之为TIME-WAIT Assassination。是的,TIME-WAIT状态自杀。
- 一个处于TIME-WAIT 状态的连接收到一个不可接受的旧数据段(序列号在接收窗口之外),TCP响应一个ACK消息(!!惊,该去复习下流程),告诉对方自己能接受的序列号,然而,对方早已发送过FIN,于是以RST响应该ACK,当一个RST到达TIME-WAIT 状态的连接时,TCP立即关闭连接 0 0 ——-它自杀了
- RFC建议TIME-WAIT 时的状态忽略RST,似乎并未被官方采用
Item 23 服务器应该设置SO_REUSEADDR选项
这个##Item是仅读标题就知道他要说的东西,服务器挂掉立即重启时,会bind失败,提示
地址已经被使用,原因是:
- TCP TIME-WAIT状态,不允许重新启动,因为前面的连接处于TIME-WAIT状态
- TCP连接由四元组指定,{local ip,local port,peer ip,peer port},本来就算立即启动服务使用相同端口也不会有任何问题,所以为何要限制新服务的启动?
- 问题出在SOCKET API上,需要调用两个函数来完全指定连接地址在,在调用bind函数时,并不知道将会调用connect,即使调用了也不知道他是指定一个连接或使用已经存在的那个。
- SO_REUSEADDR是危险的吗?
Item 24 滑动窗口
利用滑动窗口,可以轻松实现端到端的流量控制。
SWA(sliding window algorithm)是为了提高网络传输利用率而设计的。如果没有SWA,为了保证TCP有序可靠传输,发送端必须等待上一个包的ACK到达后才能继续发送,此时信道利用率是较低的(在设计redis/db读写操作时,也有类似问题,我们使用pipeline流水线机制来提高吞吐量)。
SAW的实现很简单,但saw扯上nagle算法,糊涂窗口,ACK发送时机,拥塞窗口,问题变得复杂了。
|1 2 3 4|5 6 7
| win |
1 2 3 |4 5 6 7|
^ | win |
ack
流量控制机制是网络可用性的重要保证,接收方根据能力动态调整发送方滑动窗口大小,以此控制发送速度。
接收端慢,导致糊涂窗口
明显是速率不匹配,此时滑动窗口是可以协调好速率,但问题来了:
0—>接收方慢慢地发读了一个字节,
—>空出一个位置,通告给发送方
1—>发送方立即发送一个字节
2—>接收方窗口立即被填满
3—>转0
这就是糊涂窗口综合症,极大浪费了网络带宽(ACK发送时机也有这个问题)。
解决糊涂窗口问题
问题出在接收端,只要限制接收端通告小窗口即可提高信道利用率。(注意,这并不影响吞吐量,因为此时接收端buffer是满的),
1.接收方等到可用空间=总空间一半或者最大报文段时更新窗口通告。(这样发送方就可以一次发一坨数据了,提高了信道利用率。)(注意此时他其实也回复了ACK,但没更新窗口通告)
发送方发送的数据小的糊涂窗口应对办法
发送方每次发送的数据很小(如在远程桌面时使用鼠标键盘,数据包必然很小),如果此时接收方立即回复确认ACK,发送方窗口滑动,于是又发送很小的数据,往复循环,浪费网络流量。
方法1:接收方推迟回复确认ACK包,可解决这个问题,此时发送方就能一次滑动较大窗口。
方法2:发送方使用组块技术(nagle算法),其实就是拼大点的包一次发送。
Nagle算法以及不适用场景
Nagle算法行为是发送一个data,等ack,此时将要发送的数据放到buffer,直到ack到达,将buffer内一坨数据发送出去。
对于实时场景,Nagle算法不适用,比如x-window服务,鼠标移动balabalalalalala
拥塞窗口与通知窗口
许可窗口 = min(拥塞窗口,通知窗口),前者由网路上的路由器设定,后者是由接收方控制。这里要展开来说也有一坨,光靠TCP滑动窗口并不能很好保证网络可用性,因为TCP是端到端的协议,换句话说,他只看到两端,协商两端窗口大小,根本没考虑到达对端的路径上是否有这么大的容量。我们需要能反映路径容量的窗口——拥塞窗口。
之前说TCP看不到路由器,看不到网络路径容量,决定了TCP的拥塞控制必须是试探性的方式。对了,再好的路由器,只要接入网络,必然会拉低网络总带宽。
慢启动 VS 快重传,快恢复,拥塞控制的策略